One of the things I need in my new job is a bunch of blazingly fast daemons to capture market information and trade data. I prototyped them in Ruby to see what comes down the line, but I have the need, the need for speed. Which means I need a UNIX C or C++ framework.
So I went old-school. Retro even. Plain old C++. My favorite programmer’s editor. And the good old terminal, er, iTerm 2, just Mac-like.
Since I am planning on creating a lot of these little projects, developing them on my Mac and deploying them to Linux servers, I decided to create a generic project folder layout and generic Makefile for each. And share it with you.
The Project Folder Tree
Note: I’m not making these to go outside my company, so the full GNU C++ standard project is overkill. Much of what follows does conform to the basics of their standard C++ project design though.
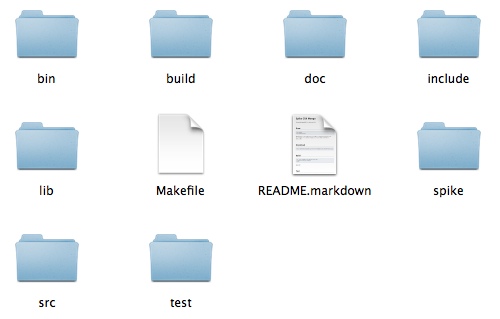
For each application, the folders are:
- bin: The output executables go here, both for the app and for any tests and spikes.
- build: This folder contains all object files, and is removed on a
clean. - doc: Any notes, like my assembly notes and configuration files, are here. I decided to create the development and production config files in here instead of in a separate
configfolder as they “document” the configuration. - include: All project header files. All necessary third-party header files that do not exist under
/usr/local/includeare also placed here. - lib: Any libs that get compiled by the project, third party or any needed in development. Prior to deployment, third party libraries get moved to
/usr/local/libwhere they belong, leaving the project clean enough to compile on our Linux deployment servers. I really use this to test different library versions than the standard. - spike: I often write smaller classes or files to test technologies or ideas, and keep them around for future reference. They go here, where they do not dilute the real application’s files, but can still be found later.
- src: The application and only the application’s source files.
- test: All test code files. You do write tests, no?
.gitignore
Since I use git for source code control, the .gitignore file is:
# Ignore the build and lib dirs
build
lib/*
# Ignore any executables
bin/*
# Ignore Mac specific files
.DS_Store
Makefile
I do not need the extra effort or platform independence of autotools. These are great for users, but suck up developer time to make them work. Instead, I opted for a simple yet flexible and generic makefile (see notes below):
#
# TODO: Move `libmongoclient.a` to /usr/local/lib so this can work on production servers
#
CC := g++ # This is the main compiler
# CC := clang --analyze # and comment out the linker last line for sanity
SRCDIR := src
BUILDDIR := build
TARGET := bin/runner
SRCEXT := cpp
SOURCES := $(shell find $(SRCDIR) -type f -name *.$(SRCEXT))
OBJECTS := $(patsubst $(SRCDIR)/%,$(BUILDDIR)/%,$(SOURCES:.$(SRCEXT)=.o))
CFLAGS := -g # -Wall
LIB := -pthread -lmongoclient -L lib -lboost_thread-mt -lboost_filesystem-mt -lboost_system-mt
INC := -I include
$(TARGET): $(OBJECTS)
@echo " Linking..."
@echo " $(CC) $^ -o $(TARGET) $(LIB)"; $(CC) $^ -o $(TARGET) $(LIB)
$(BUILDDIR)/%.o: $(SRCDIR)/%.$(SRCEXT)
@mkdir -p $(BUILDDIR)
@echo " $(CC) $(CFLAGS) $(INC) -c -o $@ $<"; $(CC) $(CFLAGS) $(INC) -c -o $@ $<
clean:
@echo " Cleaning...";
@echo " $(RM) -r $(BUILDDIR) $(TARGET)"; $(RM) -r $(BUILDDIR) $(TARGET)
# Tests
tester:
$(CC) $(CFLAGS) test/tester.cpp $(INC) $(LIB) -o bin/tester
# Spikes
ticket:
$(CC) $(CFLAGS) spikes/ticket.cpp $(INC) $(LIB) -o bin/ticket
.PHONY: clean
Notes on the Makefile:
- The
TODOat the top reminds me that I am using a different version of a library in development and it must be removed before deployment. - The
TARGETis the main executable of the project, in this casebin/runner. Typemakeand this is what gets built. - I’m using
g++because it’s the same on Mac OS X and on the production Linux boxes. - If I uncomment the
clangline, I get a failed link as the libraries are incompatible (or comment out the last line under$(TARGET):). But then I get the benefit of aclangstatic analyzer run help me make my code better, well worth it. - I use the fewest number of compiler
CFLAGSwhen developing as possible, optimization happens later. - The
SOURCESlist is dynamic, I don’t want to manually have to maintain this list as I program. Anything in thesrcfolder will be included in the compile as long as it has aSRCEXTextension. - The
OBJECTSlist is also dynamic and uses a Makefile trick to build the list based on available sources. - The
LIBin this case uses a local library for MongoDB as I am testing it, but uses the default homebrew or yum installed libraries for boost. I normally do not use boost, but Mongo needs it. - The
INCensures all headers in theincludefolder are accessible. - I like to see the commands that run, hence the multitude of
@echo's. - Since there are so few of them, I manually add spikes and test builds as a new Makefile target, see the
ticket:target for example. - The
.PHONYclean is brilliant, it nukes the build folder and the main executable. It does not clean spike or test executables though.
Aside: Why separate the includes and the sources? This is fundamentally not necessary for most of my expected projects as they will be stand-alone daemons. But I do expect to build a few shared libraries for these daemons, and having the include files separate makes them easier to deploy later on. So I may as well get into the practice of keeping them separate.
Retro Programming
So the retro code-compile-run loop looks like this:
- Code in TextMate 2.
- ⌘⇥ to a terminal and
make. - ⌘⇥ Fix any errors in TextMate 2.
- ⌘⇥ to a terminal and
makeagain until it compiles. - Type
bin\runner paramsin terminal to run the application. Tip: Use shell!expansion:!balone means that I have to type even less to run the last executable with the same parameter list.
There is nothing fancy about this setup, but that is the whole point. A simple, retro environment for simple retro C++ programs.
Follow the author as @hiltmon on Twitter and @hiltmon on App.Net. Mute #xpost on one.